1. Loading Data: BatchVectorizer and Dictionary¶
Detailed description of all parameters and methods of BigARTM Python API classes can be found in Python Interface.
- BatchVectorizer:
Before starting modeling we need to convert you data in the library format. At first you need to read about supporting formats for source data in Input Data Formats and Datasets. It’s your task to prepare your data in one of these formats. As you had transformed your data into one of source formats, you can convert them in the BigARTM internal format (batches of documents) using BatchVectorizer class object.
Really you have one more simple way to process your collection, if it is not too big and you don’t need to store it in batches. To use it you need to archive two variables: numpy.ndarray n_wd with 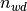 counters and corresponding Python dict with vocabulary (key - index of
counters and corresponding Python dict with vocabulary (key - index of numpy.ndarray, value - corresponding token). The simpliest way to get these data is sklearn CountVectorizer usage (or some similar class from sklearn).
If you have archived described variables run following code:
batch_vectorizer = artm.BatchVectorizer(data_format='bow_n_wd',
n_wd=n_wd,
vocabulary=vocabulary)
If you have data in UCI format (e.g. vocab.my_collection.txt and docword.my_collection.txt files), that were put into the same directory with your script or notebook, you can create batches using the following code:
batch_vectorizer = artm.BatchVectorizer(data_path='',
data_format='bow_uci',
collection_name='my_collection',
target_folder='my_collection_batches')
The built-in library parser converted your data into batches and covered them with the BatchVectorizer class object, that is a general input data type for all methods of Python API. The batches were places in the directory, you specified in the target_folder parameter.
If you have the source file in the Vowpal Wabbit data format, you can use the following command:
batch_vectorizer = artm.BatchVectorizer(data_path='',
data_format='vowpal_wabbit',
target_folder='my_collection_batches')
The result is fully the same, as it was described above.
Note
If you had created batches ones, you shouldn’t launch this process any more, because it spends many time while dealing with large collection. You can run the following code instead. It will create the BatchVectorizer object using the existing batches (this operation is very quick):
batch_vectorizer = artm.BatchVectorizer(data_path='my_collection_batches',
data_format='batches')
- Dictionary:
The next step is to create Dictionary. This is a data structure containing the information about all unique tokens in the collection. The dictionary is generating outside the model, and this operation can be done in different ways (load, create, gather). The most basic case is to gather dictionary using batches directory. You need to do this operation only once when starting working with new collection. Use the following code:
dictionary = artm.Dictionary()
dictionary.gather(data_path='my_collection_batches')
In this case the token order in the dictionary (and in further 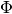 matrix) will be random. If you’d like to specify some order, you need to create the vocab file (see UCI format), containing all unique tokens of the collection in necessary order, and run the code below (assuming your file has
matrix) will be random. If you’d like to specify some order, you need to create the vocab file (see UCI format), containing all unique tokens of the collection in necessary order, and run the code below (assuming your file has vocab.txt name and located in the same directory with your code):
dictionary = artm.Dictionary()
dictionary.gather(data_path='my_collection_batches',
vocab_file_path='vocab.txt')
Take into consideration the fact that library will ignore any token from batches, that was not presented into vocab file, if you used it. Dictionary contains a lot of useful information about the collection. For example, each unique token in it has the corresponding variable - value. When BigARTM gathers the dictionary, it puts the relative frequency of this token in this variable. You can read about the use-cases of this variable in further sections.
Now you have a dictionary. It can be saved on the disk to prevent it’s re-creation. You can save it in the binary format:
dictionary.save(dictionary_path='my_collection_batches/my_dictionary')
Or in the textual one (if you’d like to see the gathered data, for example):
dictionary.save_text(dictionary_path='my_collection_batches/my_dictionary.txt')
Saved dictionary can be loaded back. The code for binary file looks as following:
dictionary.load(dictionary_path='my_collection_batches/my_dictionary.dict')
For textual dictionary you can run the following code:
dictionary.load_text(dictionary_path='my_collection_batches/my_dictionary.txt')
Besides looking the content of the textual dictionary, you also can moderate it (for example, change the value of value field). After you load the dictionary back, these changes will be used.
Note
All described ways of generating batches automatically generate dictionary. You can use it by typing:
batch_vectorizer.dictionary
If you don’t want to create this dictionary, set gather_dictionary parameter in the constructor of BatchVectorizer to False. But this flag will be ignored if data_format == bow_n_wd, as it is the only possible way to generate dictionary in this case.