2. Base PLSA Model with Perplexity Score¶
Detailed description of all parameters and methods of BigARTM Python API classes can be found in Python Interface.
At this moment you need to have next objects:
- directory with
my_collection_batchesname, containing batches and dictionary in binary filemy_dictionary.dict; the directory should have the same location with your code file; Dictionaryvariablemy_dictionary, containing this dictionary (gathered or loaded);BatchVectorizervariablebatch_vectorizer(the same we have created earlier).
If everything is OK, let’s start creating the model. Firstly you need to read the specification of the ARTM class, which represents the model. Then you can use the following code to create the model:
model = artm.ARTM(num_topics=20, dictionary=my_dictionary)
Now you have created the model, containing 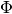 matrix with size “number of words in your dictionary”
matrix with size “number of words in your dictionary” 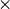 “number of topics” (20). This matrix was randomly initialized. Note, that by default the random seed for initialization is fixed to archive the ability to re-run the experiments and get the same results. If you want to have another random start values, use the seed parameter of the
“number of topics” (20). This matrix was randomly initialized. Note, that by default the random seed for initialization is fixed to archive the ability to re-run the experiments and get the same results. If you want to have another random start values, use the seed parameter of the ARTM class (it’s different non-negative integer values leads to different initializations).
From this moment we can start learning the model. But typically it is useful to enable some scores for monitoring the quality of the model. Let’s use the perplexity now.
You can deal with scores using the scores field of the ARTM class. The score of perplexity can be added in next way:
model.scores.add(artm.PerplexityScore(name='my_first_perplexity_score',
dictionary=my_dictionary))
Note, that perplexity should be enabled strongly in described way (you can change other parameters we didn’t use here). You can read about it in Scores Description.
Note
If you try to create the second score with the same name, the add() call will be ignored.
Now let’s start the main act, e.g. the learning of the model. We can do that in two ways: using online algorithm or offline one. The corresponding methods are fit_online() and fit_offline(). It is assumed, that you know the features of these algorithms, but I will briefly remind you:
- Offline algorithm: many passes through the collection, one pass through the single document (optional), only one update of the matrix on one collection pass (at the end of the pass). You should use this algorithm while processing a small collection.
- Online algorithm: single pass through the collection (optional), many passes through the single document, several updates of the matrix during one pass through the collection. Use this one when you deal with large collections, and with collections with quickly changing topics.
We will use the offline learning here and in all further examples in this page (because the correct usage of the online algorithm require a deep knowledge).
Well, let’s start training:
model.fit_offline(batch_vectorizer=batch_vectorizer, num_collection_passes=10)
This code chunk had worked slower, than any previous one. Here we proceeded the first step of the learning, it will be useful to look at the perplexity. We need to use the score_tracker field of the ARTM class for this. It remember all the values of all scores on each matrix update. These data can be retrieved using the names of scores.
You can extract only the last value:
print model.score_tracker['my_fisrt_perplexity_score'].last_value
Or you are able to extract the list of all values:
print model.score_tracker['my_fisrt_perplexity_score'].value
If the perplexity had convergenced, you can finish the learning process. In other way you need to continue. As it was noted above, the rule to have only one pass over the single document in the online algorithm is optional. Both fit_offline() and fit_online() methods supports any number of document passes you want to have. To change this number you need to modify the corresponding parameter of the model:
model.num_document_passes = 5
All following calls of the learning methods will use this change. Let’s continue fitting:
model.fit_offline(batch_vectorizer=batch_vectorizer, num_collection_passes=15)
We continued learning the previous model by making 15 more collection passes with 5 document passes.
You can continue to work with this model in described way. Now one note: if you understand in one moment that your model had degenerated, and you don’t want to create the new one, then use the initialize() method, that will fill the matrix with random numbers and won’t change any other things (nor your tunes of the regularizers/scores, nor the history from score_tracker):
model.initialize(dictionary=my_dictionary)
FYI, this method is calling in the ARTM constructor, if you give it the dictionary name parameter. Note, that the change of the seed field will affect the call of initialize().
Also note, that you can pass the name of the dictionary instead of the dictionary object whenever it uses.
model.initialize(dictionary=my_dictionary.name)