6. Tokens Co-occurrence and Coherence Computation¶
- Interpretability and Coherence of Topics
The one of main requirements of topic models is interpretability (i.e., do the topics contain tokens that, according to subjective human judgment, are representative of single coherent concept). Newman at al. showed the human evaluation of interpretability is well correlated with the following automated quality measure called coherence. The coherence formula for topic is defined as
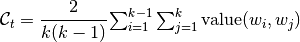 ,
,
where value is some pairwise information about tokens in collection dictionary, which is provided by user according to his goals.
- Tokens Co-occurrence Dictionary
BigARTM provides ability of automatic coherence computation. The only thing you should prepare is file with co-occurrences of tokens (to know how to gather a co-occurrence dictionary using BigARTM CLI, please read BigARTM Command Line Utility). Lines of that file should have the next format:
id1 id2 value
where id1 and id2 are indexes of tokens in vocabulary file in UCI format (with 0-based indexing!). Details about UCI format can be found here: Input Data Formats and Datasets. value is some pairwise information about tokens with indexes id1 and id2. For instance, value can be computed by any corpora of texts by formulas:
- positive PMI:
![value(u,v)=\left[\log\cfrac{n(u,v)n}{n(u)n(v)}\right]_{+}](../../_images/math/701b456c7b603e9889a38f0ba687b1b6d79674c7.png) ,
, - smoothed logarithm of conditional probability:
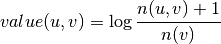 ,
,
where n(u) and n(v) are frequencies of u and v in corpora, n(u,v) is joint frequency of u and v in corpora in window with some fixed width, n is length of corpora in words.
- Usage
Let’s assume you have file cooc.txt with co-occurrences of tokens. Also you should have vocabulary file in UCI format vocab.txt corresponding to cooc.txt file.
To upload co-occurrence data into BigARTM you should use artm.Dictionary object and method gather:
cooc_dict = artm.Dictionary()
cooc_dict.gather(
data_path='batches_folder',
cooc_file_path='cooc.txt',
vocab_file_path='vocab.txt',
symmetric_cooc_values=True)
Where
data_pathis path to folder with your collection in internal BigARTM format (batches);cooc_file_pathis path to file with co-occurrences of tokens;vocab_file_pathis path to vocabulary file corresponding to cooc.txt;symmetric_cooc_valuesis Boolean argument.Falsemeans that co-occurrence information is not symmetric by order of tokens, i.e. value(w1, w2) and value(w2, w1) can be different.
So, now you can create coherence computation score:
coherence_score = artm.TopTokensScore(
name='TopTokensCoherenceScore',
class_id='@default_class',
num_tokens=10,
topic_names=[u'topic_0',u'topic_1'],
dictionary=cooc_dict)
Arguments:
nameis name of score;class_idis name of modality, which contains tokens with co-occurrence information;num_tokensis numberkof used top tokens for topic coherence computation;topic_namesis list of topic names for coherence computation;dictionaryis artm.Dictionary with co-occurrence statistic.
To add coherence_score to the model use next line:
model_artm.scores.add(coherence_score)
To access to results of coherence computation use, for example:
model.score_tracker['TopTokensCoherenceScore'].average_coherence
General explanations and details about scores usage can be found here: 3. Regularizers and Scores Usage.