Enabling Basic BigARTM Regularizers¶
This paper describes the experiment with topic model regularization in BigARTM library using experiment02_artm.py. The script provides the possibility to learn topic model with three regularizers (sparsing Phi, sparsing Theta and pairwise topic decorrelation in Phi). It also allows the monitoring of learning process by using quality measures as hold-out perplexity, Phi and Theta sparsity and average topic kernel characteristics.
Warning
Note that perplexity estimation can influence the learning process in the online algorithm,
so we evaluate perplexity only once per 20 synchronizations to avoid this influence.
You can change the frequency using test_every variable.
We suggest you to have BigARTM installed in $YOUR_HOME_DIRECTORY.
To proceed the experiment you need to execute the following steps:
Download the collection, represented as BigARTM batches:
- https://s3-eu-west-1.amazonaws.com/artm/enwiki-20141208_1k.7z
- https://s3-eu-west-1.amazonaws.com/artm/enwiki-20141208_10k.7z
This data represents a complete dump of the English Wikipedia (approximately 3.7 million documents). The size of one batch in first version is 1000 documents and 10000 in the second one. We used 10000. The decompressed folder with batches should be put into
$YOUR_HOME_DIRECTORY. You also need to move there the dictionary file from the batches folder.The batch, you’d like to use for hold-out perplexity estimation, also must be placed into
$YOUR_HOME_DIRECTORY. In our experiment we used the batch named243af5b8-beab-4332-bb42-61892df5b044.batch.The next step is the script preparation. Open it’s code and find the declaration(-s) of variable(-s)
home_folder(line 8) and assign it the path$YOUR_HOME_DIRECTORY;batch_size(line 28) and assign it the chosen size of batch;batches_disk_path(line 36) and replace the string ‘wiki_10k’ with the name of your directory with batches;test_batch_name(line 43) and replace the string with direct batch’s name with the name of your test batch;tau_decor,tau_phiandtau_theta(lines 57-59) and substitute the values you’d like to use.
If you want to estimate the final perplexity on another, larger test sample, put chosen batches into test folder (in
$YOUR_HOME_DIRECTORYdirectory). Then find in the code of the script the declaration of variablesave_and_test_model(line 30) and assign itTrue.After all launch the script. Current measures values will be printed into console. Note, that after synchronizations without perplexity estimation it’s value will be replaced with string ‘NO’. The results of synchronizations with perplexity estimation in addition will be put in corresponding files in results folder. The file format is general for all measures: the set of strings «(accumulated number of processed documents, measure value)»:
(10000, 0.018) (220000, 0.41) (430000, 0.456) (640000, 0.475) ...
These files can be used for plot building.
If desired, you can easy change values of any variable in the code of script since it’s sense is clearly commented. If you used all parameters and data identical our experiment you should get the results, close to these ones
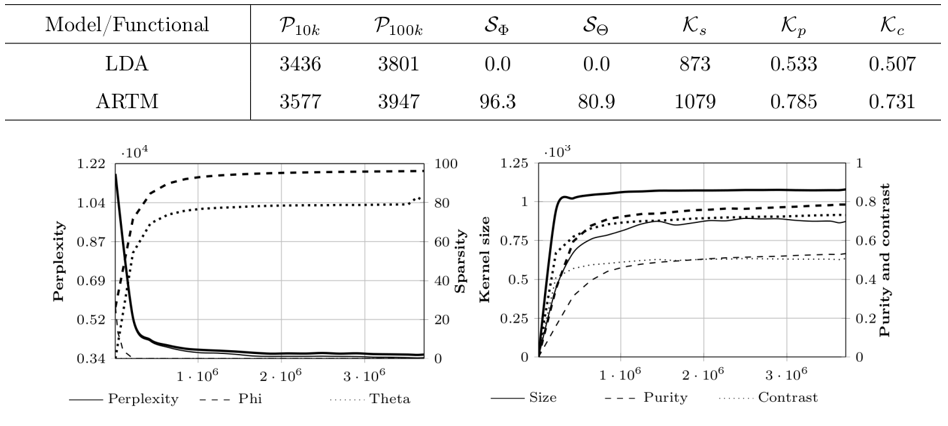
Here you can see the results of comparison between ARTM and LDA models. To make the experiment with LDA instead of ARTM you only need to change the values of variables tau_decor, tau_phi and tau_theta to 0, 1 / topics_count and 1 / topics_count respectively and run the script again.
Warning
Note, that we used machine with 8 cores and 15 Gb RAM for our experiment.